引っ越し!
読者の皆様,いかがお過ごしでしょうか?昨年はブログ毎月更新を目標にしながらも,まさかの1年ぶり投稿させていただきます(笑)相変わらずのやるやる詐欺だな~...と苦笑いしながらも,今年こそはもう少し更新します.目標は4半期に1度更新!( ゚Д゚)
で,管理が煩わしいことと1人で細々と仕事を受けるスタンスなので,会社のホームページを作ってなかったのですが,せっかくなのでブログを簡易的な会社紹介の場所にもしてしまおうと思いまして,はてなブログの法人プランに申し込んでそちらでブログを書いていくことにしました.まだ記事は書けてませんが...
codeeye-robotics.hatenablog.com
この機会に,今までの記事をリライトしてから新しいほうに移そうと思ったのですが,おそらくやるやる詐欺になると思うので(笑),そのまま新しいほうに移してこちらを閉じようと思っています.ただ,タイトルも同じなので,記事を上げ始めればすぐに見つかると思います.また暇つぶしにでも見てやってくださいませ.
それでは,2024年もよろしくお願いします!目指せ年4回以上更新( ゚Д゚)
IMAX と新海誠
5万人の読者の皆様,いかがお過ごしでしょうか?ジモトモに,「ブログの更新が無さ過ぎて生きてるのか死んでるのかわからんわ!」と言われ,今年は月2回,,,,いや月1回は更新したいと思っている社長でございます(笑)
新海誠監督
IT関連の仕事を生業としているワタクシですが,流れの早いIT業界にいる割には世間のトレンドについていけておらず...どのくらいついていけてないかというと,2022年11月の段階で「君の名は」を見て「新海誠サイコー(≧∇≦)/」って言ってるくらい,ついていけてないんです(笑)
新海監督の何がそこまで響いたのかといいますと,映画そのものがよかったということももちろんあるのですが,「監督」「原作」「脚本」「絵コンテ」「撮影」「編集」...と作品の結構な部分を担当していて,ここまで自分のオリジナルで勝負するのすごいなと大分感銘を受けまして.ブログに書こうと思ってたんですがなんやかんやで年明けになってしまいました.
一応モノづくりを生業としているワタクシ,まだまだ先人のキャッチアップとか模倣でヒーヒーの状態ですが,少しずつオリジナルの味を出せるように,精進しなければと思った次第でございます.
新海監督のキャリアパス
だいぶ感銘&刺激を受けたこともあり,ちょっとググってみたんですが,新海監督の今までのキャリアパスがざっくりと書かれたインタビュー記事を発見.「君の名は」が公開される前のインタビューなので今ほどの認知度はないと思うのですが,脱サラオタク系男子にはとっても響く内容になってます.
おすすめ記事です.
next.rikunabi.com
天職とファーストキャリア
記事を読んで,大成功しているような映画監督が最初からアニメーション映画製作狙い撃ちではなく,仕事をやりながら方向を絞り込んでいってる点が結構意外でした.「ゲームのムービー」を会社員としての仕事としてやって,結果的にそのスキルが「アニメーション制作」に生きたというところをみて,ファーストキャリアの選択時点である程度ざっくりとした方向性が決められれば,あとは多少のズレを許容しても結果的に振り返ればスキルが積みあがっていくんだなあと.あと,退職してアニメーション制作に舵を切ったという点も結構示唆的で,一定のスパン(期間)で方向性の微調整を自分で考え,行動しないといけないんだなあと改めて思いました.
全然レベルは違うものの(笑),自分の場合を振り返ってみても,やりたいことの方向性(ソフトウェア開発)を何となく決めて,あとは短期的にはやることにこだわり過ぎず雑食でやったことで,結果として今振り返ったら自分のスキルになっているなあと思うことが結構あります.自分の場合は何回か転職してますが,転職が結果的に方向性の微調整をもたらしてくれたかなと.なので,最初の選択の時点ではあまり厳密に決まってなくても,大きな方向性がずれていなければ,やりながら微調整をするのが一番王道なんだなあと改めて思いました.まあ,この「大きな方向性」を決めるのが大事で,かつ難しかったりするんだと思いますが...
新海監督過去3作品と「すずめの戸締り」
話が飛びましたが,肝心の映画のほうはといいますと,ちょうど「すずめの戸締まり」の公開直前だったこともあって,弊社の城下町(笑),市川妙典イオンの IMAX で新海監督の3作品「秒速5センチメートル」「君の名は」「天気の子」を上映してまして,試しに一つ見てみたらドハマりしてしまいまして,結局「すずめの戸締り」まで全部見てしまいました.映画の評価に関してはもはやネットで賛否両論議論されているので,ここでは省かせていただきます.ただ,新海監督の作品,アラフォー青春真っ直中男子には大分響きますね.(笑)
ということで,なんだか内容がとっ散らかってしまいましたが(笑),この言葉で記事を締めくくりたいと思います.
「来世は東京のイケメン男子にしてくださ〜い!」
謹賀新年2023!
推定5万人の僕のブログ読者の皆様,あけましておめでとうございます!新年になってしまいましたが,いかがお過ごしでしょうか??
社長はといいますと,年末は仕事納めに若干失敗し(笑)1月2日くらいまでバタバタしてましたが何とか目途がつきまして,豊洲のチームラボプラネッツを見に行くも現地でチケット売り切れに気づいて断念からの,成田山初詣&ウナギを食すからの,「ルージュの伝言」爆音で聞きながらの,夜の東京湾アクアラインドライブを満喫してきました.まあ,オカンのリクエストだったんですが(笑)
ここまでとこれから!
2020年に会社を設立して今年の4末で3回目の決算になるのですが,2021年からはラッキーなことに複数のお客さんから仕事をいただくようになりまして,忙しくも充実した感じでここまできました!ただ,悲壮感のある忙しさでは全くないものの,ずっと机に向かう感じになっているので,今年は仕事に加えてちょっと新しいことをやってみて,味変できないかな~と思っています.現状考えている "味変アイテム" が3つありまして,,,
味変アイテム
1.海外取引にトライする!ための準備をする(笑)
以前からちょくちょく「目標!」ってな感じでブログに書いてたやつですが,海外取引をどうやるかを真剣に検討します.税務と法律をざっくり調べるところからスタートして,そこがクリアできたとして,実際にはお客さんをゲットしないといけないので,,,ちょっと発信していかないといけないんですが,技術的に結構深い内容のブログを英語できっちり書いて(もちろん勉強して)数を残していけばなんか引っかかるような気がしているのですが,「技術ブログをきっちり書いて,数を膨らませる」ことがかなり大変なので,,,ちょっと味変というよりは,スープを全部いれかえるような感じになってしまいそうですね(笑)
2.数学を勉強する!
今後のエンジニアライフを考えてみたとき,数学をきっちり勉強してみるのは結構意味があるかなと思ってるんですが,さすがに仕事を止めて大学に行くほどの選択は取りずらく..どうしたものかと思ってたんですが,東京理科大の理学部数学科が夜間コースを提供していることを発見!「アラフォー男子,大学に舞い戻る.」をやってみるのもありかなと.社会人枠だと2年次 or 3年次から編入できて,願書と面接だけでOKなんですよね(笑)ただ願書の締め切りが1月19日でして,即断即決が求められます(; ・`д・´)
3.ロボットの勉強に時間をがっつり取る
こちらはもちろん参加8回目,今年こそは完走したいつくばチャレンジのことです(笑)筑波大の偉大な先輩方&Tier4の優秀なエンジニアの方々のおかげでロボットはそこそこ走るようになったものの,OSSの中身の理解がいま一歩な感じでして,今年は本番まで時間をがっつりとって,主要なアルゴリズムをロボットを動かしながら勉強してみたい!ただ,走らせるところが無いという問題がありまして,千葉のどこかに半年くらい貸倉庫を借りられると素敵だなあと思っています.ちなみに「千葉貸倉庫.com」という,法人向けに賃貸用の貸倉庫を仲介しているサイトがありまして,最近ワクワクしながらしょっちゅう見ています(笑)が,これがかなり高く,,,こちらもどうするか悩み中です.
で,どうする!?
ということで,味変アイテムを3つ考えてたんですが,1はちょっと今年は重すぎるなと(笑).あと,この3年間は割と仕事(アウトプットを前提としたインプット)中心だったので,勉強(アウトプットを前提としないインプット)する時間も取りたいなという思いもありまして,2と3で悩んでいます.が,書いた通り2は願書締め切りが1月19日でして,今年の予定がまだちょっと不透明なこともあって,さすがに今から即断即決即実行はちょっとつらいなあ...といった感じです.ということで,おそらく3になると思うのですが...こちらはまたブログにアップします.


2022年,折り返し!
9月,,,終わりました.会社の決算月は4月なので,正確には折り返し月まではあと1か月あるんですが,納品というかマイルストン的には折り返し地点まで来た感じですね.ふー.
ここまで,実家のゴタゴタやら仕事やらで結構忙しくしてまして,怒涛でした _(:3 」∠)_
話のネタが仕事以外にないので(笑),今回はちょっと趣を変えます!
断酒
お酒を飲むと割とめんどくさくなることをご存知の方々からは驚かれると思うんですが(笑),実は2年半前からお酒を断ってまして,それからお酒飲んでません!(一滴も飲んでないというと嘘になりますが(笑))
断酒自体は成功したんですが,何がつらいってストレス発散の方法がなくなってしまいまして.なんていうか,,,その,,,お酒飲まないのにキャバクラとか,,,ガールズバーとか,,,行けないじゃないですか(笑)
映画鑑賞
で,気分転換する方法を模索した結果,映画館で没入すると結構効果があることがわかりまして,ここ1年くらい片っ端から映画を見ています.昔は割と洋画を中心にというか映画館ではほぼ洋画しか見ない人だったんですが,結構なペースで映画館に行くので見る映画がなくなってしまって,邦画も結構見ています.さすがにプリキュアとかはまだ手を出してませんが(笑)
韓国の映画とかも時々上映してまして,評価が高そうなものは都内まで見に行ったりしているんですが,韓国映画すごいですね.興行的に成功するかどうかは作品の良し悪し以外にもいろんな要因があるので簡単ではないと思いますが,そのまま欧米に輸出しても通用しそうな気がします.作品のレベルでみると日本と韓国で大分差がついてしまっているような....日本で上映されている時点で韓国での興行成績がいいのもだけを選んでると思うんですが,今年ベストの日本映画と比較しても結構つらいような気がします...
2022の5本!
ということで勝手に今年の映画ランキングですが,
1.アルピニスト
伝説のアルピニストの映画で,ドキュメンタリーです.アルピニストって憧れるんですよね~.自分はビビりなので絶対無理ですけど....
2.モガディシュ 脱出までの14日間
ソマリア内戦に巻き込まれた韓国と北朝鮮の大使館員が協力してソマリアを脱出します.いい意味で,映像がハリウッドの作品みたいです.
3.流浪の月
李相日監督の作品が結構好きで,「悪人」「怒り」も見たのですが,自分的にはこの作品が一番良かったです.ただ,興行成績はそれほどいかなかったみたいですが.
4.CODA
アカデミー作品賞受賞!
5.ジュラシック・ワールド/新たなる支配者
物語はもはやグダグダですが(笑),映像はさすがですね!何も考えずに,スカッとできます.
番外編.今夜世界からこの恋が消えても
大分年齢層が若かったので映画館に入るの迷ったんですけど,高校生に混じっておっさんも見てきました(笑)コテコテの恋愛物ですが,よかったです.キュンキュンしたい人はどうぞ(笑)
でした!皆様,時間があればぜひご覧ください!
2022後半戦!
後半戦開始です!前半戦はやられ気味でつくばチャレンジの準備が全然できてませんが,,,,参加することに意義がある!ということで(笑)ここから挽回します(-ω-)/
ということで皆様,2022年後半戦も頑張っていきましょう!

謹賀新年2022!
5万人の読者の皆様!いかがお過ごしでしょうか?
大分遅くなってしまいましたが(笑),あけましておめでとうございます!
社長は変わらず元気にやってます(゚Д゚)ノ
昨年はゴールデンウィークからずっとブログ更新できてなかったのですが,有難くも「ブログ更新してないじゃないですか(・´з`・)」と言ってもらったので,アップすることにしました!ただ,しばらく書いてないと何を書いていいかわからなくなりますね...ということで,ぎこちないですがお許しをm(__)m
2021年度ですが,実はいろいろとありまして,なかなか忙しくも充実した時間を過ごしてました!
【2021年のモロモロ】
1.1人オフィスの近くに引っ越し.(流山市ー>船橋市)
もうだいぶたちましたが,引っ越しました!南流山に別れをつげて,やってきました船橋市.
2.つくばチャレンジのスポンサーになる.& 会社のロゴ作成
なりました!最後の写真をご覧あれ(笑)
3.つくばチャレンジ完走.
ロボット的には本当にあとちょっとのとこまで来ました!2022こそは完走を!
4.お客さん&売上を増やす!
お客さんに恵まれたこともあって,運よくチャレンジできることになりました.ということで,絶賛仕事マラソン実施中です!本当に仕事一色の生活を送っています(笑)
やりたいことリスト!
今年のやりたいことリスト!ですが,期限を切らずにやっているので,結局昨年のアイテムをほぼそのまま持ってきた感じになっています(笑)想定以上に仕事中心の生活になっているので,勉強ネタがほとんど進まないですが,,,今年も(有難くも)仕事中心になりそうです.
【仕事ネタ】
1.海外から仕事をとってくる!
ここ2~3年のスパンで一つの目標にできればと思っています!ただ,税務とか法律とかが全く分からないので,ひとまず宣言だけ(笑)
【勉強ネタ】
1.つくばチャレンジのスポンサーになる.
引き続きスポンサーになります!
2.つくばチャレンジ完走.
今年こそは完走します!(笑)
3.ブログのリライト.
昔のエントリを見ていると結構嘘くさい(笑)ことを書いているので,復習もかねてリライトしたい!
4.SFMをやりきる.
うーん.散発的にしかできてない....
5.ディープラーニングを勉強する.
うーん.やりたい.が,始められない.
6.数学力強化!
うーん.散発的にしかできてない....
7.年に4本のブログアップ
うーん.ブログのアップが思った以上に進まず...あまり欲張らずに四半期に一度アップを目指します.
2022年!
ということで,今年もいままで通り,
All life is an experiment. The more experiments you make the better.
Ralph Waldo Emerson
をモットーに,いろんな実験をしていけたらと思います!ではでは,今年もよろしくお願いします!

うたの日コンサート
沖縄に,,,,行きたい行きたい行きた~い.
ということで沖縄病を発症してまして,BEGINと夏川りみばっかり聞いてます(笑)
2年くらい前のアナザースカイにBEGINが出演してたんですが,2001年から沖縄慰霊の日の翌日を歌の日として,「うたの日コンサート」というのを毎年開催しているみたいです.調べたところ結構有名なコンサートみたいで,一度行ってみたいと思っているのですが,昨年はコロナでオンラインになってしまい...今年こそは!と思ってひそかに予定をたててたんですが,どうやら延期になってしまったようです...
ただ,中止ではないみたいなので,タイミングが合えば行ってみたいなあ.
5.バンドル調整 〜 直線探索
ここでは,最適化に必要となる直線探索を扱います.これが,,,,なかなかに込み入ってて,とっても面倒でした.ただ,Numerical Optimization で紹介されているアルゴリズムの多くが直線探索に依存していたので,,,思い切って突っ込んで調べてみることにしました.簡単に実装はしてみたのですが,処理の流れを追う程度で見て頂ければと思います.実際に直線探索を作る必要がある方は, Ceres Solver とかを参考にしてみてください.
直線探索が必要になるとき
最急降下法を用いた時の収束の様子をイメージした図が下記になります.
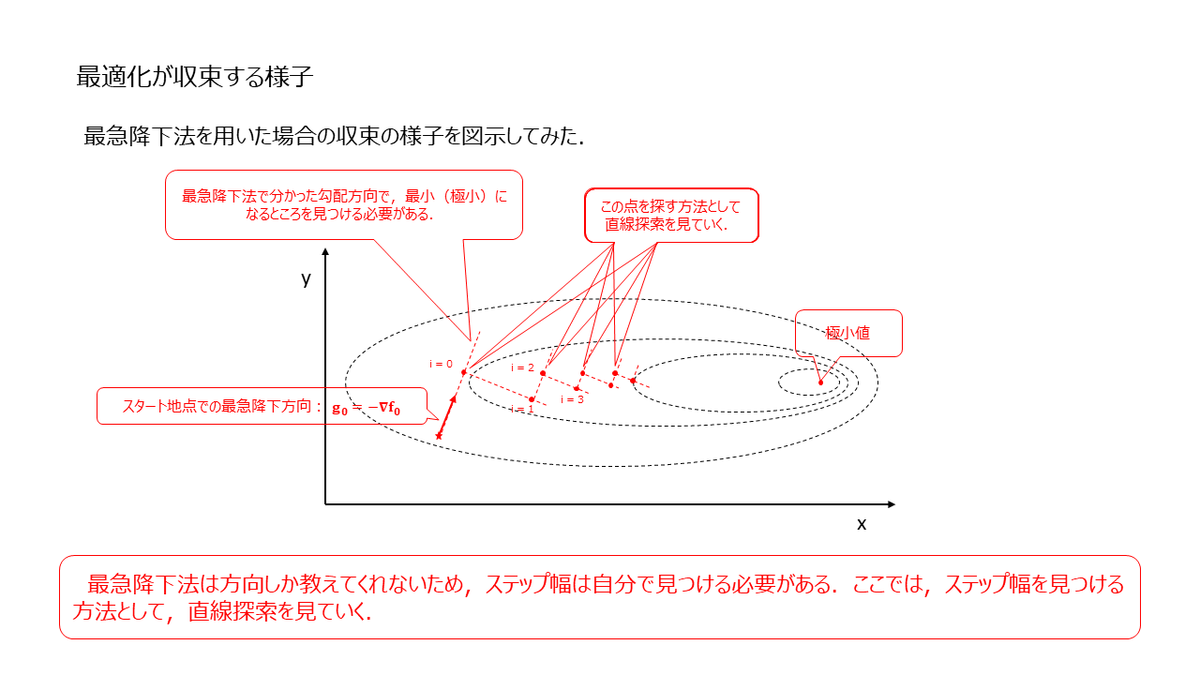
図からもわかるように,上手くいけば反復毎に最適値へと近づいていくことになります.ここで,方向(ステップ方向)は計算式によって与えられるものの,その方向にどれだけ進めばよいか(ステップ幅)は明示的に与えられないため,実験的に確かめて決めていく必要があります.これを実現する方法を直線探索と言って,関数の値が "前提条件" を満たすまで,所定の方向に沿っていろんなステップを試します.

次に,先ほど言及した "前提条件" ですが,この前提によって直線探索は "Exact Line Search" と "Inexact Line Search" にわかれます.
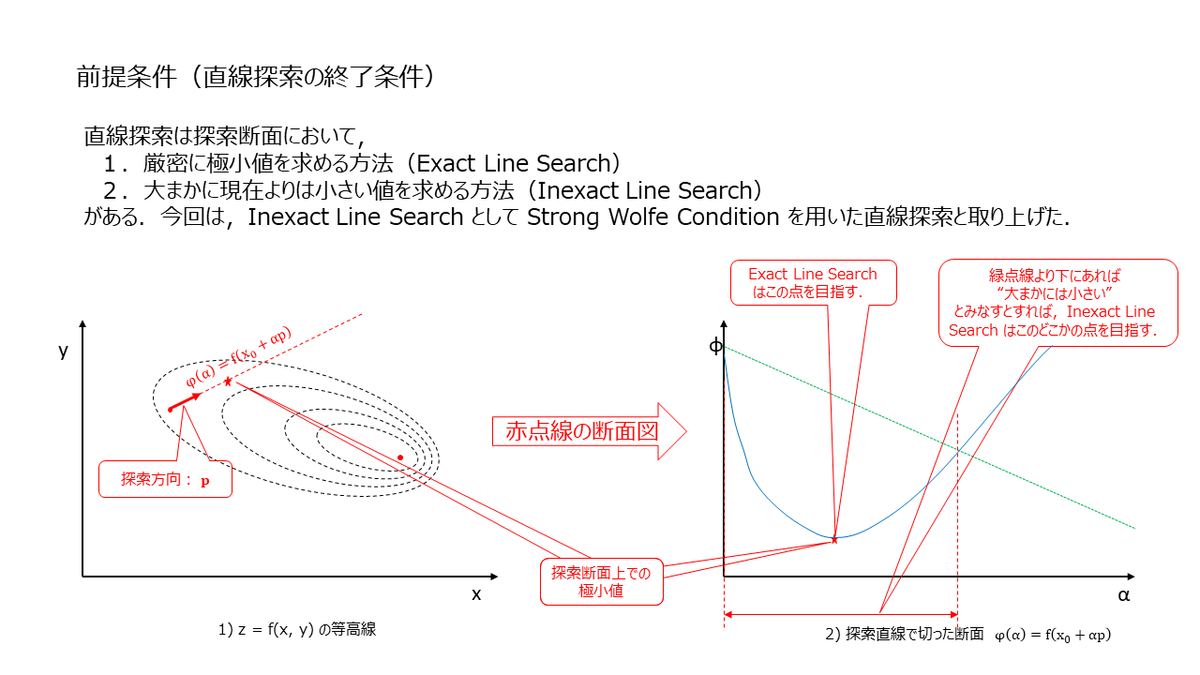
Exact Line Search はステップ方向に沿って厳密に極小値を求めていくため,必然的に実行時間が長くなります.ただ,実際には毎ステップ厳密に極小値を求めなくても最適値にはたどりつくようで,多くの最適化ソフトウェアでは Inexact Line Search が使われているようです.今回は,Numerical Optimization と Ceres Solver を参考に勉強したので,"前提条件" として Strong Wolfe Condition を使った直線探索を見ていきたいと思います.
Strong Wolfe Condition
Strong Wolfe Condition は下記の条件になります.
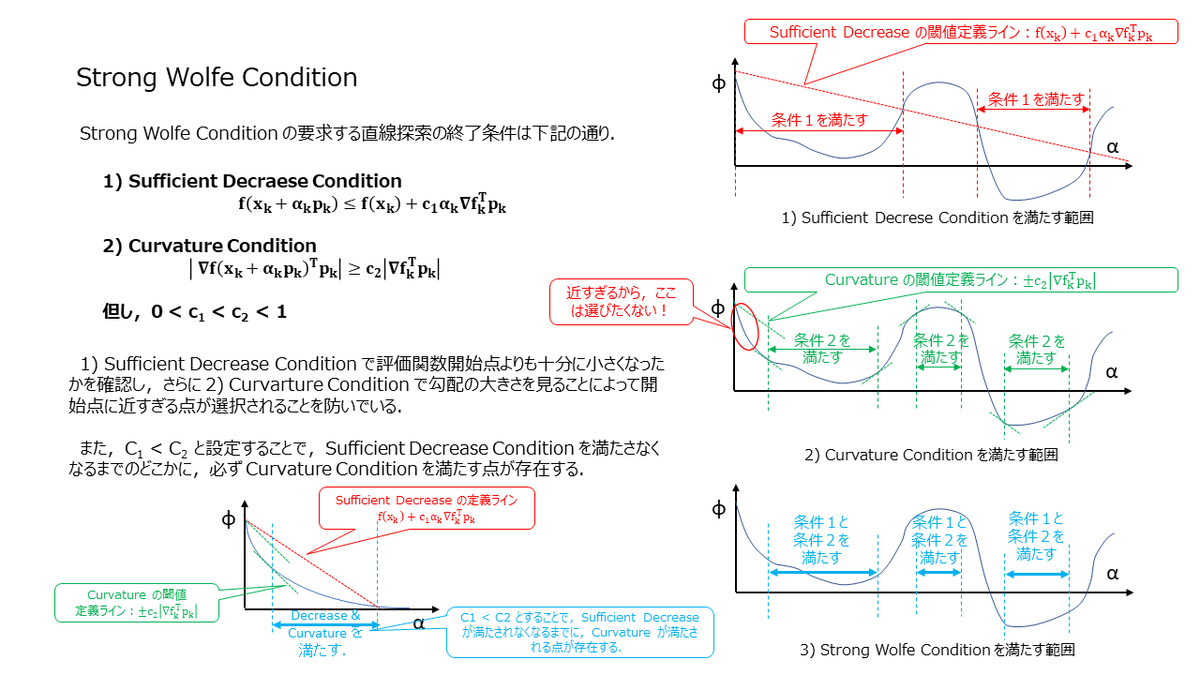
スライドにも記載のある通り,Curvature Condition を設定することによって,開始点に近すぎる点が次の計算点として選択されることを防いでいます.
Strong Wolfe を実装した直線探索法
これが思った以上にめんどくさく,とっても時間がかかったんですが(笑),スライドに挙動を起こしてみました.
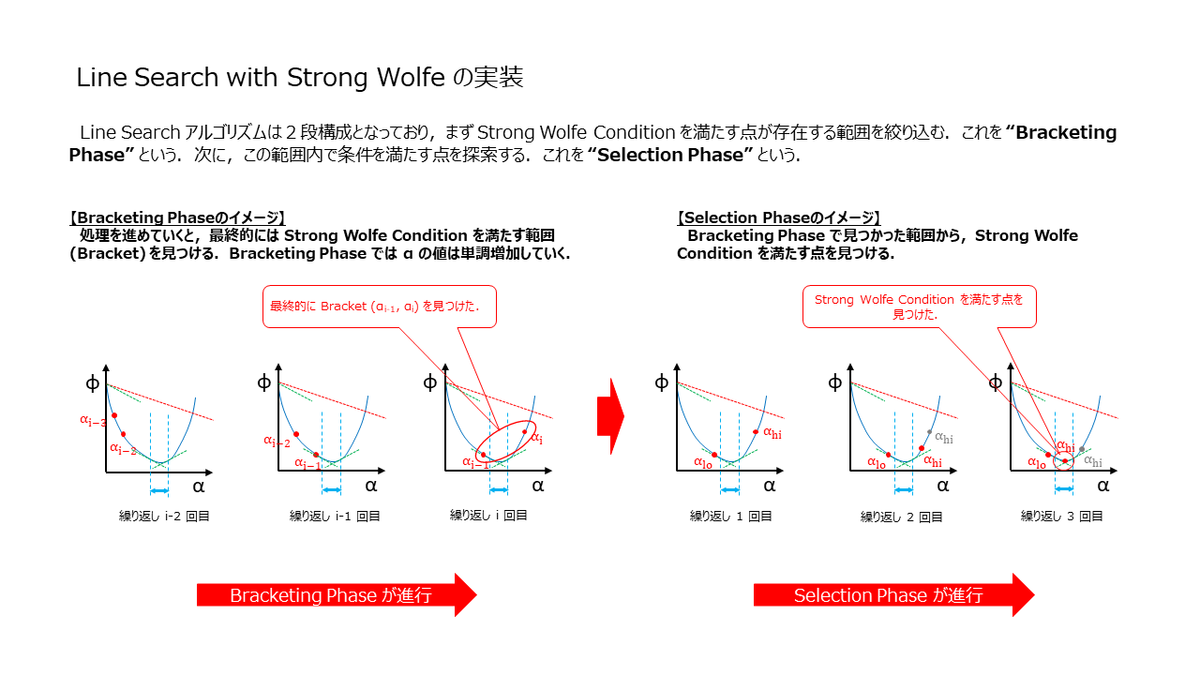
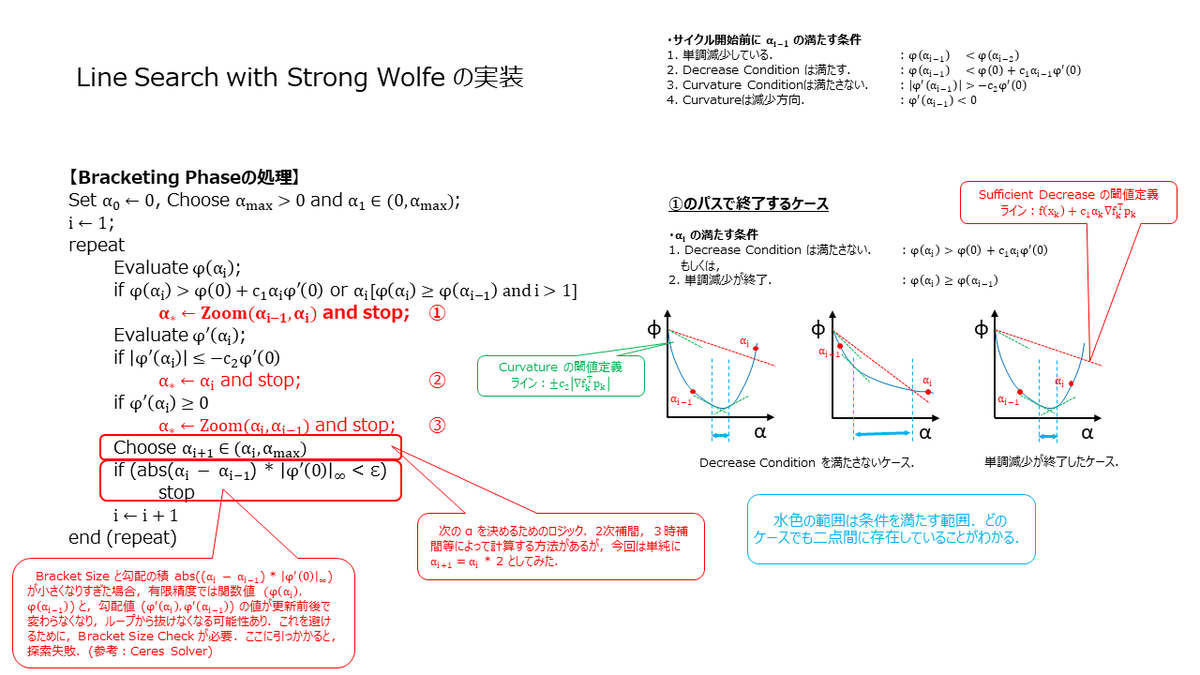
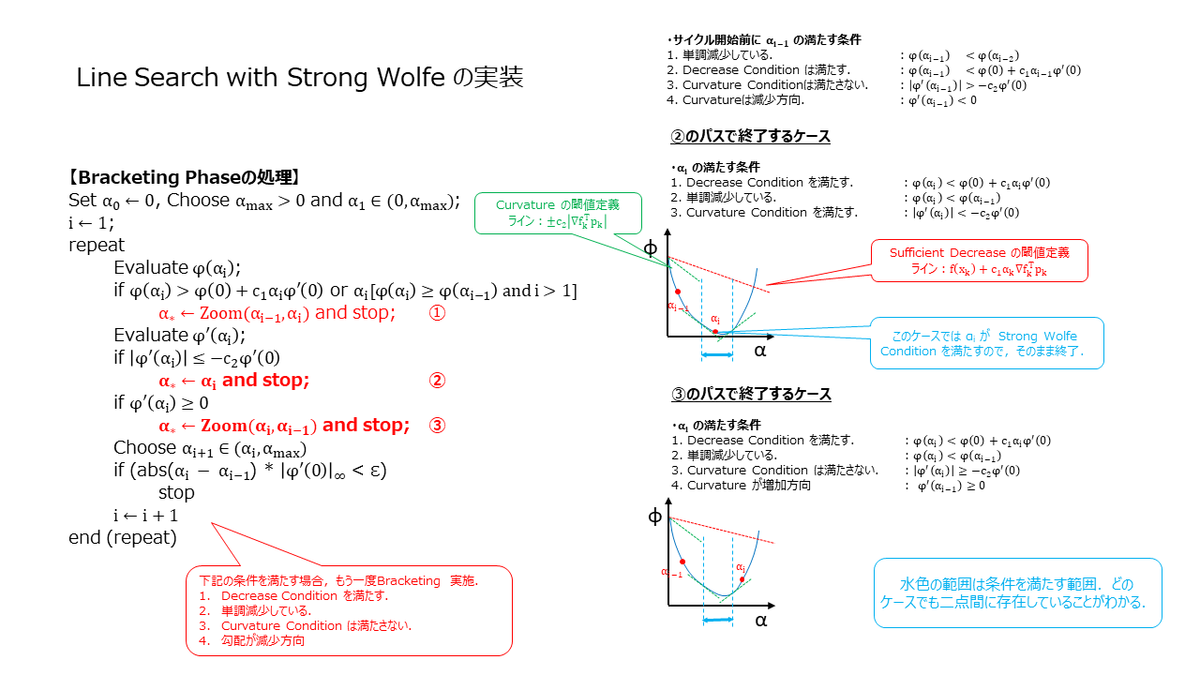
直線探索の実装は,Bracketing Phase と Selection Phase という2つの Phase に分かれます.まず,Bracketing Phase が走り,次に Selection Phase が走るのですが,それぞれの Phase でやっていることは,下記の様になります.
Bracketing Phase : Strong Wolfe Condition を満たすであろう点の存在する範囲(上記スライドの水色範囲)を探索する.
Selection Phase : Bracekting Phase で挟み込んだ範囲から,Strong Wolfe Condition を満たす点を探し出す.
となります.
Bracketing Phase の実装
ここでは,Bracketing Phase の実装を見ていきます.この Phase では範囲の絞り込みをやっています.いくつかケースを書き出して,図にしてみました.あと,実際にこのアルゴリズムを走らせる場合は数値計算的な部分(有限精度)も考慮する必要がありまして,範囲が狭くなりすぎるとループから抜けられなくなります.Bracket Size Check とスライドに記載した部分が該当の箇所になります.
bool LineSearchWithStrongWolfe( const std::vector<Track>& tracks_src, const std::vector<Eigen::Matrix3d>& K_src, const std::vector<Eigen::Vector3d>& T_src, const std::vector<Eigen::Vector3d>& Rot_src, const std::vector<Eigen::Vector3d>& points3d_src, const std::map<size_t, size_t>& extrinsic_intrinsic_map, size_t max_itr, double min_step, double alpha_max, double c1, double c2, double& alpha_star) { // X. Temporary buffer. std::vector<Eigen::Vector3d> T_tmp = T_src; std::vector<Eigen::Matrix3d> K_tmp = K_src; std::vector<Eigen::Vector3d> Rot_tmp = Rot_src; std::vector<Eigen::Vector3d> points3d_tmp = points3d_src; // X. Compute base value & base gradient. double phi_0 = ComputeReprojectionError( tracks_src, K_tmp, extrinsic_intrinsic_map, Rot_tmp, T_tmp, points3d_tmp); Eigen::MatrixXd grad_0 = ComputeGradient(K_tmp, T_tmp, Rot_tmp, points3d_tmp, tracks_src, extrinsic_intrinsic_map); double grad_0_max_norm = grad_0.col(0).lpNorm<Eigen::Infinity>(); // X. Compute directional derivative. Eigen::MatrixXd step_dir = -grad_0.normalized(); double der_phi_0 = grad_0.col(0).dot(step_dir.col(0)); // X. Start iteration. double phi_i = phi_0; double phi_i_1 = phi_0; double der_phi_i = der_phi_0; double der_phi_i_1 = der_phi_0; // X. Initial alpha. double alpha_i_1 = 0; double alpha_i = std::min(1.0, alpha_max); // X. Status bool success = false; for (size_t itr = 0; itr < max_itr; itr++) { // X. Copy from original.. T_tmp = T_src; K_tmp = K_src; Rot_tmp = Rot_src; points3d_tmp = points3d_src; // X. Update parameters based on alpha. UpdateParameters(alpha_i * -grad_0, tracks_src, extrinsic_intrinsic_map, K_tmp, T_tmp, Rot_tmp, points3d_tmp); // X. Compute function value at alpha_i. phi_i = ComputeReprojectionError(tracks_src, K_tmp, extrinsic_intrinsic_map, Rot_tmp, T_tmp, points3d_tmp); // X. Condition 1. if (phi_i > phi_0 + c1 * alpha_i * der_phi_0 || (phi_i >= phi_i_1 && itr > 0)) { success = Zoom(tracks_src, K_src, T_src, Rot_src, points3d_src, extrinsic_intrinsic_map, alpha_i_1, alpha_i, c1, c2, max_itr, min_step, alpha_star); break; } // X. Compute gradient at alpha_i. Eigen::MatrixXd grad_i = ComputeGradient(K_tmp, T_tmp, Rot_tmp, points3d_tmp, tracks_src, extrinsic_intrinsic_map); der_phi_i = grad_i.col(0).dot(step_dir.col(0)); // X. Condition 2. if (std::abs(der_phi_i) <= -c2 * der_phi_0) { alpha_star = alpha_i; success = true; break; } // X. Condition 3. if (der_phi_i >= 0) { success = Zoom(tracks_src, K_src, T_src, Rot_src, points3d_src, extrinsic_intrinsic_map, alpha_i, alpha_i_1, c1, c2, max_itr, min_step, alpha_star); break; } // X. Bracket range can not be found. Retry with different alpha alpha_i_1 = alpha_i; alpha_i = std::min(2 * alpha_i, alpha_max); phi_i_1 = phi_i; der_phi_i_1 = der_phi_i; // X. Bracket Size Check if ((std::abs(alpha_i - alpha_i_1) * grad_0_max_norm < min_step) || (alpha_i_1 == alpha_max)) { success = false; alpha_star = alpha_i_1; break; } } return success; }
※この実装,数値計算的なところも考慮する必要があり,思った以上に込み入ってまして(笑)流れを理解するために見て頂ければと思います.確実な詳細を知りたい方は,Google 先生の下記のコードをご覧あれ.
ceres-solver/line_search.cc at master · ceres-solver/ceres-solver · GitHub
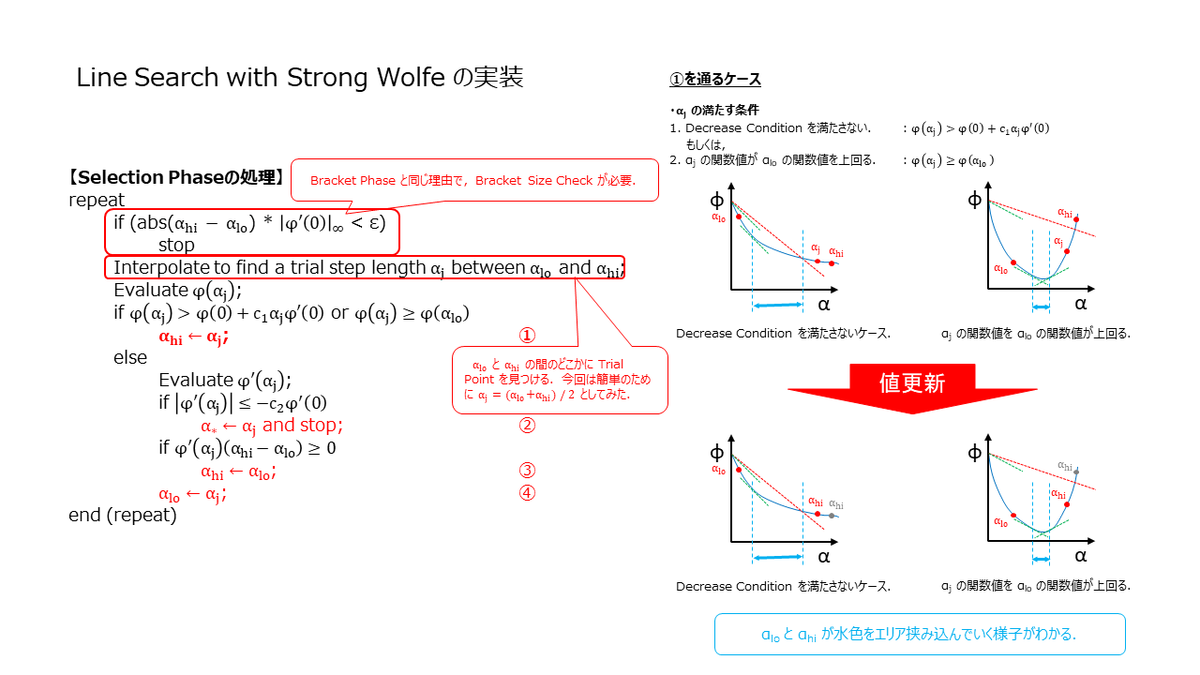
Selection Phase の実装
ここでは,Selection Phase の実装を見ていきます.Selection Phase は,Braceking Phase で Zoom(αi,αj) と記載した関数の実装になりますが,Zoom 関数に渡される時点で下記の前提が成立している必要があります.前提条件が満たされない場合,Strong Wolfe を満たす点が見つからない可能性があります.
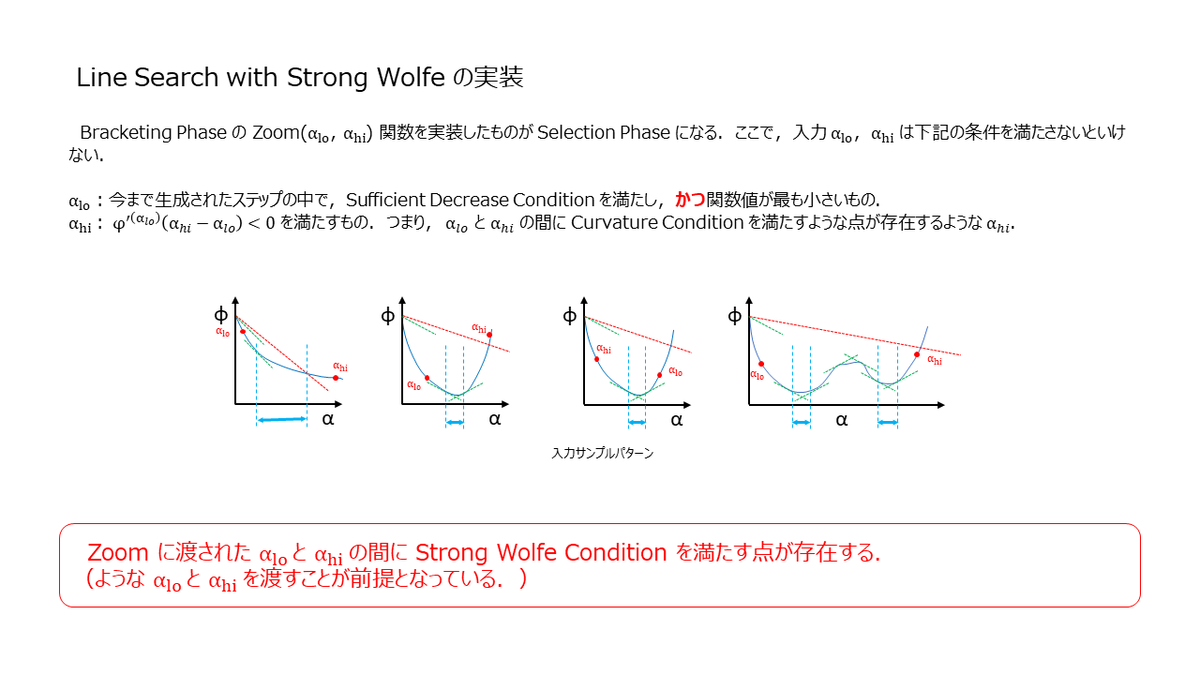
ここでも数値計算的な部分(有限精度)を考慮する必要がありまして,範囲が狭くなりすぎるとループから抜けられなくなります.Bracket Size Check とスライドに記載した部分が該当の箇所になります.また Selection Phase では,2次補間や3次補間を使って次の α を選択していましたが,今回は簡単のために中間点を使っています.

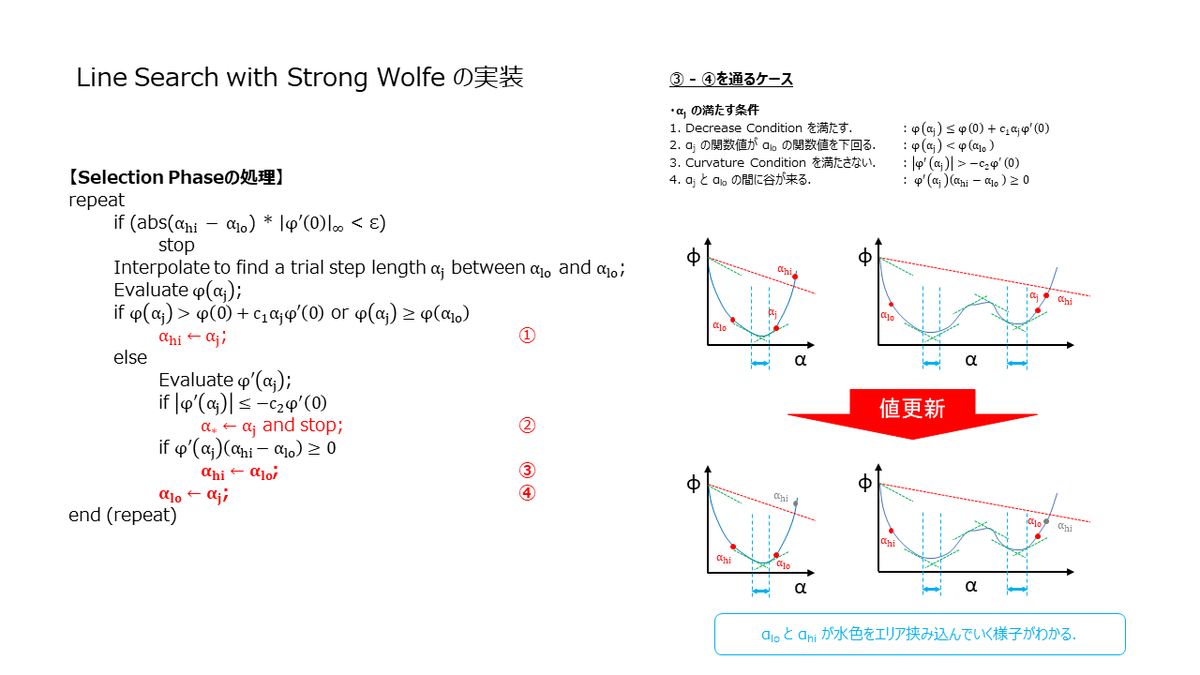
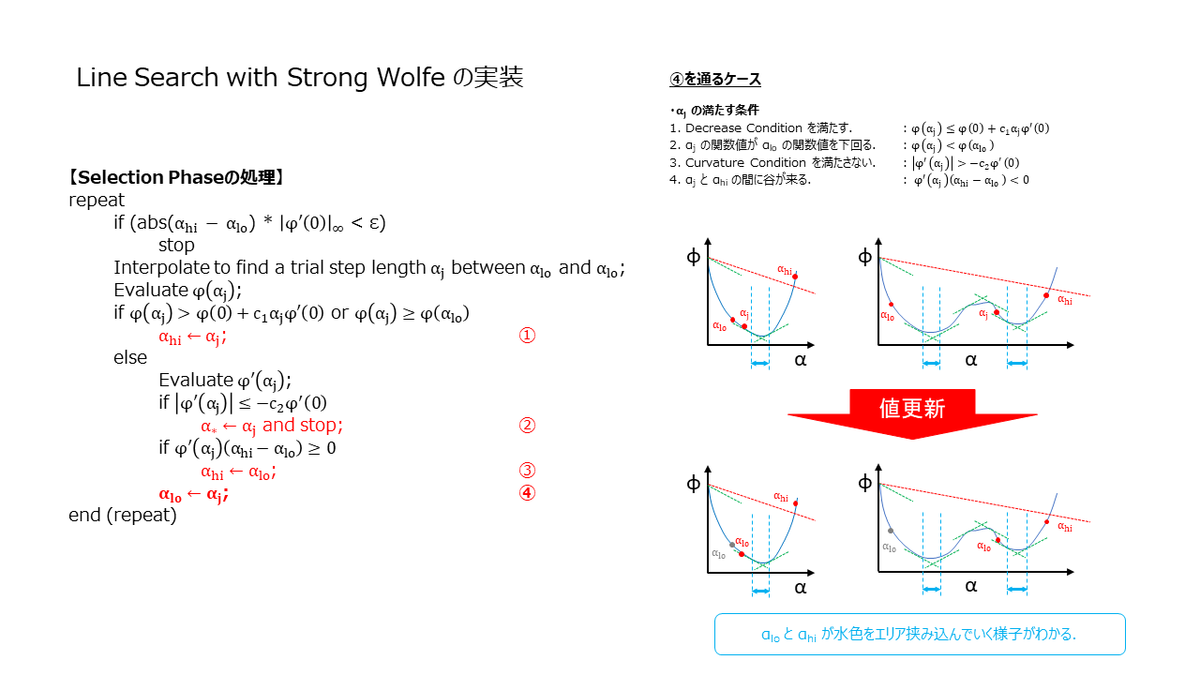
bool Zoom(const std::vector<Track>& tracks_src, const std::vector<Eigen::Matrix3d>& K_src, const std::vector<Eigen::Vector3d>& T_src, const std::vector<Eigen::Vector3d>& Rot_src, const std::vector<Eigen::Vector3d>& points3d_src, const std::map<size_t, size_t>& extrinsic_intrinsic_map, double alpha_low, double alpha_high, double c1, double c2, size_t max_itr, double min_step, double& alpha_star) { // X. Compute base value & base gradient. double phi_0 = ComputeReprojectionError( tracks_src, K_src, extrinsic_intrinsic_map, Rot_src, T_src, points3d_src); Eigen::MatrixXd grad_0 = ComputeGradient(K_src, T_src, Rot_src, points3d_src, tracks_src, extrinsic_intrinsic_map); double grad_0_max_norm = grad_0.col(0).lpNorm<Eigen::Infinity>(); // X. Compute directional derivative. Eigen::MatrixXd step_dir = -grad_0.normalized(); double der_phi_0 = grad_0.col(0).dot(step_dir.col(0)); // X. Compute value at alpha_low. double phi_lo = ComputeReprojectionErrorWithStepLength( -grad_0, alpha_low, tracks_src, K_src, T_src, Rot_src, points3d_src, extrinsic_intrinsic_map); // X. Initial alpha double alpha_low_tmp_ = alpha_low; double alpha_high_tmp_ = alpha_high; // X. Result bool success = false; for (size_t itr = 0; itr < max_itr; itr++) { // X. Bracket Size Check if ((std::abs(alpha_high_tmp_ - alpha_low_tmp_) * grad_0_max_norm < min_step)) { success = false; alpha_star = alpha_low; break; } // X. Find trial value. double alpha_j = ComputeTrialValues(alpha_low_tmp_, alpha_high_tmp_); // X. Update parameters based on alpha. std::vector<Eigen::Vector3d> T_tmp = T_src; std::vector<Eigen::Matrix3d> K_tmp = K_src; std::vector<Eigen::Vector3d> Rot_tmp = Rot_src; std::vector<Eigen::Vector3d> points3d_tmp = points3d_src; UpdateParameters(alpha_j * -grad_0, tracks_src, extrinsic_intrinsic_map, K_tmp, T_tmp, Rot_tmp, points3d_tmp); double phi_j = ComputeReprojectionError(tracks_src, K_tmp, extrinsic_intrinsic_map, Rot_tmp, T_tmp, points3d_tmp); if (phi_j > phi_0 + c1 * alpha_j * der_phi_0 || phi_j >= phi_lo) { // X. Shrink upper window. alpha_high_tmp_ = alpha_j; } else { // X. Evaluate derivative value. Eigen::MatrixXd grad_j = ComputeGradient(K_tmp, T_tmp, Rot_tmp, points3d_tmp, tracks_src, extrinsic_intrinsic_map); double der_phi_j = grad_j.col(0).dot(step_dir.col(0)); // X. Find point satisfying wolfe condition. if (std::abs(der_phi_j) <= -c2 * der_phi_0) { alpha_star = alpha_j; success = true; break; } // X. Shrink upper window. if (der_phi_j * (alpha_high_tmp_ - alpha_low_tmp_) >= 0) { alpha_high_tmp_ = alpha_low_tmp_; } // X. Shrink lower window. alpha_low_tmp_ = alpha_j; phi_lo = phi_j; } } return success; }
※この実装,数値計算的なところも考慮する必要があり,思った以上に込み入ってまして(笑)流れを理解するために見て頂ければと思います.確実な詳細を知りたい方は,Google 先生の下記のコードをご覧あれ.
ceres-solver/line_search.cc at master · ceres-solver/ceres-solver · GitHub
ふ~.ということで,次に行きます!
実験コード
目次のページ
バンドル調整はシリーズ物として書いてまして,目次は下記のページになります.
daily-tech.hatenablog.com